МОДУЛИ ДЛЯ РАБОТЫ С ТЕКСТОМ
Модуль «Обработка текста»
Модуль «Обработка текста» предлагает несколько методов сравнения текста. В некоторых задачах требуется знание о том, как сильно различен текст между эталонным и указанным. Это задачи, относящиеся к компьютерной лингвистике и искусственному интеллекту.
Интерфейс модуля
Окно модуля состоит из части составления команды, кнопок управления командами и списком команд в виде таблицы. Часть составления команды состоит из следующих полей: выпадающий список «Действие» с доступным набором методов анализа текста, два поля «Строка 1» и «Строка 2», предназначенные для ввода двух строк текста или переменных, содержащих текст, и поле «Переменная результат» - для названия переменной, в которую будет помещен результат работы модуля.
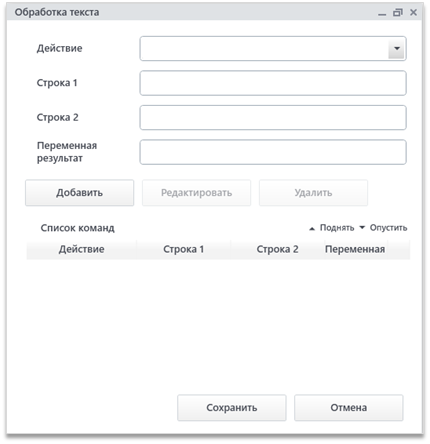
По кнопке «Добавить» созданная команда поместится в таблицу «Список команд». Для редактирования команды из списка нужно выбрать её в таблице, изменить необходимые поля и нажать на кнопку «Редактировать». Для удаления команды нужно выбрать ее в списке и нажать на кнопку «Удалить». С помощью стрелочек в углу таблицы можно менять команды местами.
Методы анализа текста
В модуле предложены следующие методы анализа текста:
-
Расстрояние Левенштейна – рассчитывает разницу между двумя строками. Например – «Lexema RPA» и «Lexema SR» отличаются на 3 символа – слова «Lexema» совпадают полностью, остальные символы различны, то есть результат, записанный в переменную, будет равен 3;
-
3-граммы – метод, основанный на работе с n-граммами, в нашем случае n=3 – оценивается схожесть каждых 3 символов. Чем больше число (до 1), тем большую схожесть имеют строки. В примере «Lexema RPA» и «Lexema SR» результатом будет число 0,52.
-
Сходство Джаро-Винклера – мера схожести строк для измерения расстояния между двумя последовательностями символов. Чем меньше расстояние Джаро-Винклера для двух строк, тем больше сходства имеют эти строки друг с другом. Для примера «Lexema RPA» и «Lexema SR» результатом будет число 0,5.
Модуль «Распознавание текста»
Модуль «Распознавание текста» предназначен для считывания текста с указанного изображения и представления полученного текста в виде объекта.
Интерфейс модуля
Модуль состоит из двух полей – «Путь к файлу» и «Переменная», и флажка «Скриншот».
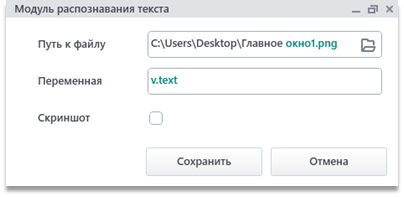
Поле «Путь к файлу». Заполняется путем до файла, который необходимо распознать. Это может быть картинка или PDF-документ.
Поле «Переменная». Заполняется названием переменной, начиная с символов «v.», в которую будет помещен результат распознавания.
Флажок «Скриншот». Флажок ставится, когда необходимо распознать скриншот экрана в момент работы данного модуля в процессе выполнения робота. В таком случае поле «Путь к файлу» указывать не нужно.
Структура результирующего объекта – массив листов документа, каждый элемент которого – объект, состоящий из двух полей – number и words. Поле number содержит в себе номер листа документа (с 1-цы), поле words представляет собой массив объектов всех слов со страницы. Структура объекта слова – value, x, y, page. В value содержится слово, в x и y координаты слова x и y соответственно, в page – номер страницы, на котором содержится слово.
ПРИМЕР.
Пусть имеется следующее изображение формата jpeg. Подадим его в модуль распознавания текста.

Результат, записанный в переменную при распознавании изображения:
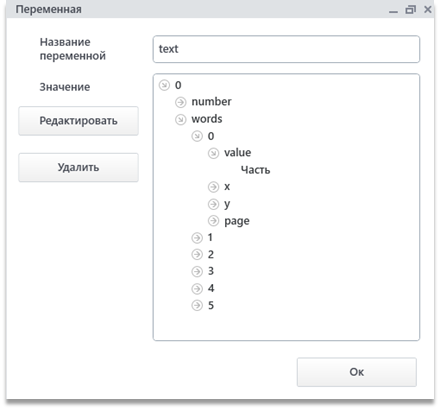
Результат содержит информацию о страницах, координате и значении каждого слова изображения.
Пример получения некоторого слова со второго листа документа: v.text[1].words[100].value, где v.text – переменная, в которую записан результат работы модуля, [1] – номер листа в документе (нумерация по переменным-спискам начинается с 0), [100] – 101-ое слово в файле, value – само значение слова.
Модуль «Распознавание текста ABBYY»
Модуль «Распознавание текста ABBYY» работает, в основном, с PDF-файлами. В отличие от предыдущего модуля имеет более высокую точность и скорость работы.
Результат распознавания записывается в переменную-объект, в которой можно обратиться к конкретной строке, таблице, слову.
Интерфейс модуля
Данный модуль состоит из двух полей – «Путь к PDF-файлу» и «Переменная».
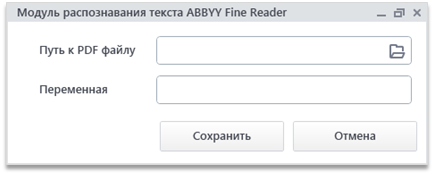
Поле «Путь к PDF файлу». В поле указывается путь до распознаваемого файла/картинки.
Поле «Переменная». В поле вводится имя переменной, начиная с символов «v.», в которую будет занесен результат распознавания.
PDF файл может состоять из нескольких страниц, поэтому переменная будет являться списком страниц. Например, v.text[0] – первая распознанная страница файла.
Весь распознанный текст делится на две части – основной текст и табличная часть.
Основной текст
Для обращения к тексту, необходимо обращаться к полю rows_word[0] (в данной записи [0] означает, что идет обращение к первой текстовой части, в других версиях ABBYY возможно использование большего разбиения текста). Затем указывается, как отдельное поле, номер строки и, через точку, номер слова в строке – v.text[0].rows_word[0].2.4. Затем, после выбора нужного слова, можно получить его значение, обратившись к полю value – v.text[0].rows_word[0].2.4.value – такая строка выдаст значение слова, находящегося на первой странице распознанного документа, во второй строке и является четвертой слева.
Табличная часть
Для обращения к таблице, необходимо обращаться к полю tables[0] ([0] нужен для корректной работы, его смысловая часть заложена в продукте ABBYY). Затем отдельным полем вводится номер таблицы, так как на странице их может быть несколько – v.text[0].tables[0].0. После этого вводится номер ячейки в таблице в виде одного числа. Если вы хотите найти ячейку и знаете её номер колонки и строки, то можно получить индекс рассматриваемой ячейки переменной в виде «строка,колонка», обратившись к полю index – v.text[0].tables[0].0.5.index (5 – пятая ячейка в массиве распознанных ячеек). Для получения значения из ячейки нужно обратиться к её значению, а затем либо собрать всю строку, записанную в ячейку, либо обратиться к конкретному слову по его порядковому номеру – v.text[0].tables[0].0.5.value.1.value – значение второго слова из пятой ячейки первой таблицы с первой страницы распознанного текста.
Для получения количества ячеек в таблице используйте следующую конструкцию – v.text[0].tables[0].0.length, то есть используйся метод «length» после того поля, после которого идет поле, количество элементов которого необходимо узнать.
Для получения количества слов в ячейке используйте v.text[0].tables[0].0.5.length.